Lessons from Building an Autonomous QA Agent
What we learned while moving TesterArmy from a prompt-based QA agent to a more predictable step-based testing system.

For the past few months our main focus at TesterArmy has been building the best agent for testing.
The reason is simple: AI is great at generating code, but it is also sloppy. It makes mistakes just like humans do. AI-native teams that ship 10x faster should not ship 100x more bugs. The goal is to help teams move fast without losing confidence in what they deploy.
Building a testing agent sounds simple at first. Give the model a browser, add a few tools, ask it to QA the app, and wait for the report. In practice, that approach breaks down quickly.
Let's go through what we learned while building ours.
The first prompt-based agent
Our first proof of concept used a simple AI SDK tool loop agent with Playwright MCP tools. Those tools connected to a cloud browser over CDP, which was enough to prove that an AI agent could drive a real app and inspect the result.
It was also enough to expose the first big problem: context overload.
The agent had to navigate the page, understand the current UI, decide what to click, remember the user goal, and reason about whether the app behaved correctly. All of that happened inside one broad loop.
For example, this prompt looks reasonable:
Go to tester.army, sign in, complete onboarding, create a new project, and make sure you can edit it.
But this asks the agent to think about everything at once:
- How to sign in
- What onboarding means in this app
- Which buttons move the flow forward
- When the project is actually created
- What counts as a successful edit
- Whether the final state should pass or fail
It felt similar to using a coding agent without a plan. Sometimes it got somewhere useful, but the result was inconsistent. Our go-to model for clicking around was Gemini 3 Flash, but even stronger models like Sonnet struggled with the same issue.
The problem was not only model quality. The task shape was wrong.
Moving to a step-based architecture
One of the most important properties of a testing agent is reproducibility. For the same test, you want the same result. You do not want a false positive because the agent got stuck somewhere strange or interpreted the goal differently on a second run.
The prompt-based architecture produced too many false positives. It was also hard to tell the agent exactly what to test and what to assert.
So we moved from a chat input box to a step-based editor. You can still prompt TesterArmy to generate the steps, but the execution is constrained into a sequence the agent can follow one step at a time.
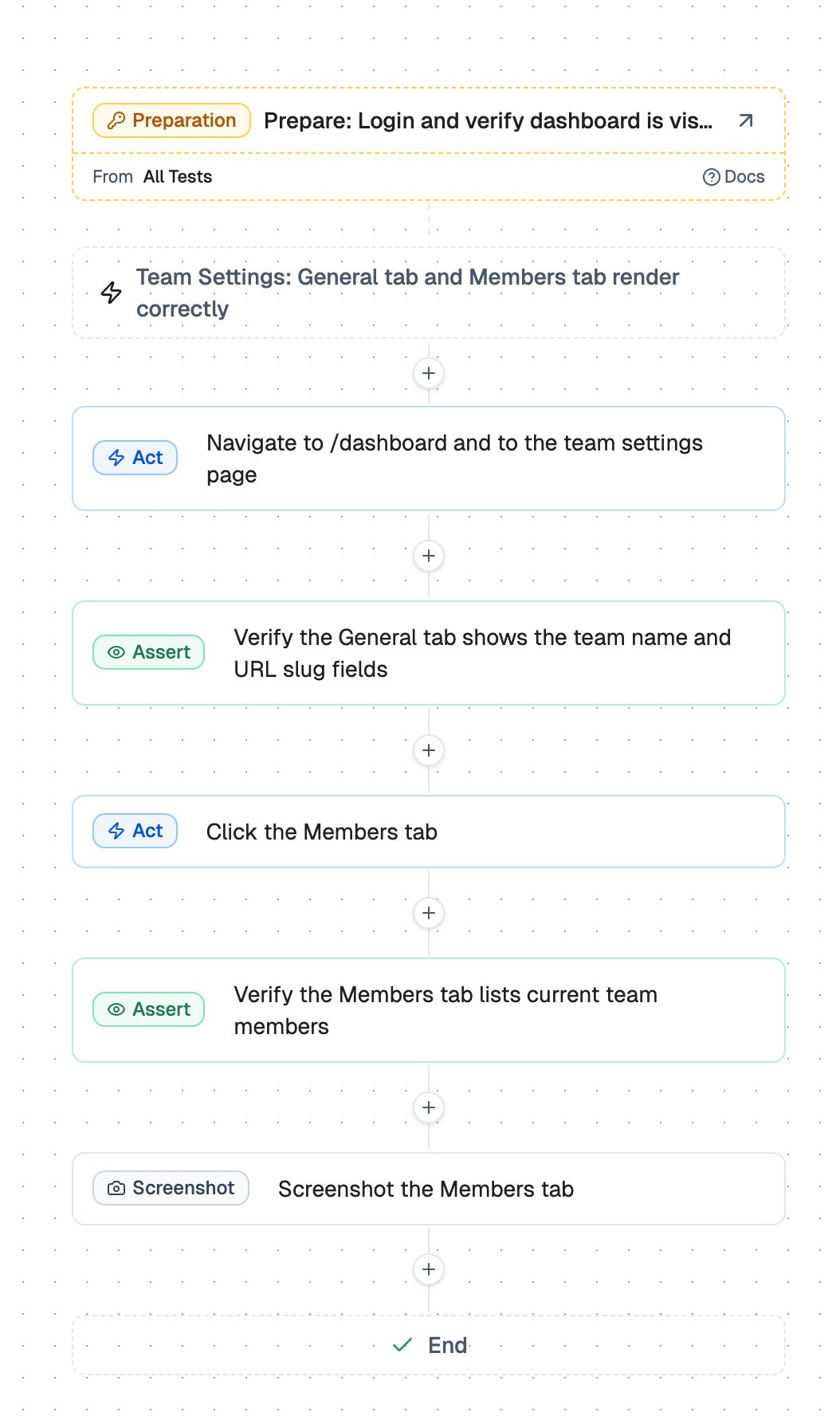
That changed the problem. Instead of asking the model to solve the entire test in one go, we ask it to complete a smaller unit of work with a clearer goal.
This makes the agent easier to reason about and much easier to debug. If a test fails, we can see which step failed, what the agent saw, what it tried, and what it concluded.
Context matters more than expected
Reducing context usage is not only about cost. It also affects speed and decision making.
In testing, an LLM with too much context can struggle with even simple flows. Details from previous steps compete with the current task. Old observations, irrelevant DOM snapshots, and prior reasoning can all make the next decision worse.
We added multiple context compaction methods because the agent does not need everything that happened before. It needs the current step, the relevant state, and enough history to avoid repeating mistakes.
A good rule of thumb when building agents is to think like an agent. Imagine trying to complete a task while someone keeps handing you irrelevant details from the previous thing you did. More context can become noise very quickly.
Better tools make better agents
Another big lesson: tool quality matters a lot.
Even a small change in a tool description can affect how an agent uses it. If a tool is too vague, the model guesses. If it overlaps too much with another tool, the model picks inconsistently. If the output is too noisy, the model spends tokens interpreting the tool instead of solving the task.
That is why we started building our own tools. We wanted full control over descriptions, execution, returned data, and failure modes.
The biggest unlock so far has been giving the agent vision-based tools that can handle edge cases where DOM-only automation is not enough. More on that soon.
What we learned so far
Here are the main takeaways from building the TesterArmy agent:
- Use AI SDK devtools to get into your agent's shoes.
- Remove irrelevant information from context aggressively.
- Run evals so regressions are caught early.
- Control your tools instead of treating them as a black box.
- More constrained agents produce more predictable results.
None of these are complicated ideas. The hard part is applying them consistently while the product and the agent evolve.
That's a wrap
Our agent is still evolving every week. We have talked to customers who tried to build the same thing in-house and eventually decided it was not worth maintaining themselves.
That matches our experience. The hard part is not making an agent click around a website once. The hard part is making it reliable, reproducible, debuggable, and useful enough to trust in real workflows.
If you want to try it, TesterArmy is open for sign-ups: sign in.


